ナレッジ
ナレッジノードを使用して、ベクトルデータベースからコンテキストを取得する方法を学びます。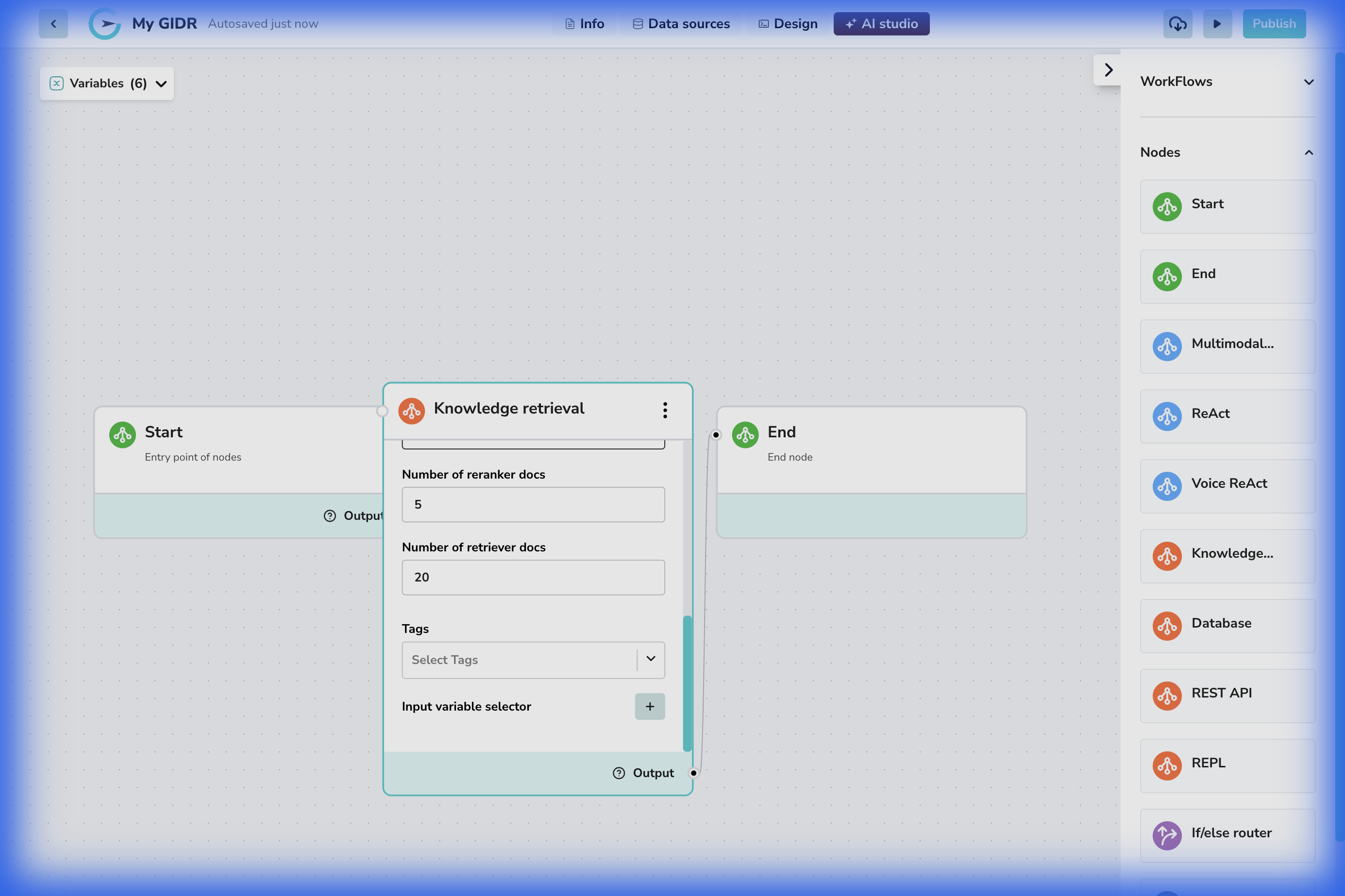
概要
ナレッジ ノード(「ナレッジ検索」とも呼ばれます)は、ワークフローとベクトルデータベースの間の架け橋です。入力クエリに基づいて関連するドキュメントチャンクを見つけるためにセマンティック検索を実行し、特定のデータに基づいてAIの応答を根拠付けることができます。 返される結果の数を制御し、タグでフィルタリングできます。設定
基本設定
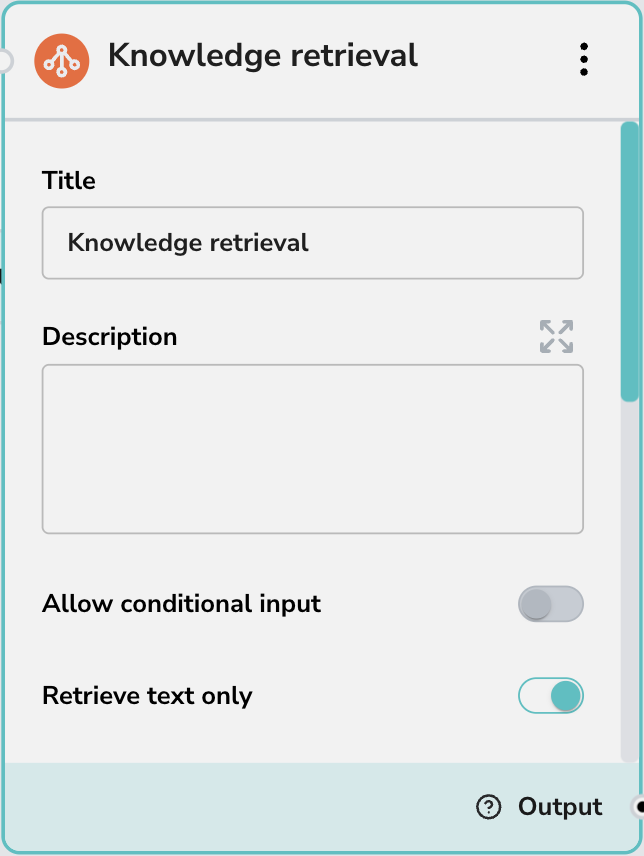
- タイトル: ノードの表示名(デフォルト:「Knowledge retrieval」)。
- 説明: この特定の検索ノードが検索する内容を説明するためのオプションの説明。
検索パラメータ
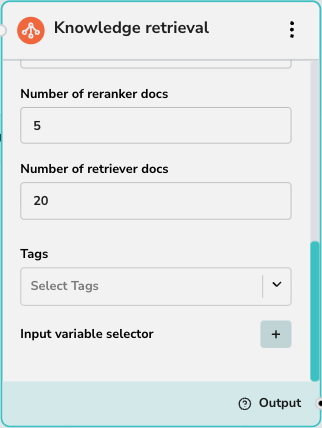
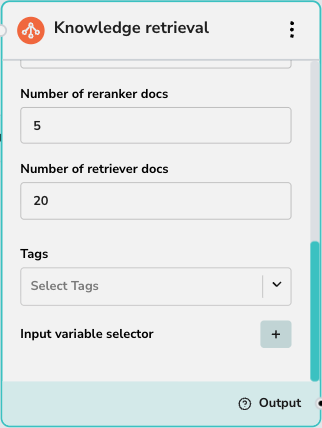
これらの設定は、結果の質と量を制御します:- 再ランクプロバイダー: 使用する再ランク付けモデルを選択します(例:Cohere)。再ランク付けは、初期結果を再スコアリングすることで関連性を向上させます。
- 再ランクドキュメント数: 再ランク付けモデルに渡すドキュメントの数。
- 検索ドキュメント数: 再ランク付けの前にベクトルデータベースから取得する初期ドキュメント数。
ナレッジベースの選択 (タグ)
- タグ: このドロップダウンを使用して、検索するナレッジベースを選択します。これはフィルターとして機能し、選択したタグに関連付けられたドキュメントに検索を制限します。
入力
- 入力変数セレクター: 検索をトリガーする入力を定義します。通常、これはユーザーのクエリ (
sys.query) または前のノードからの出力です。
追加オプション
- テキストのみ取得: 有効にすると、検索出力をテキストコンテンツのみに制限するトグル(常に
texts出力を選択することと同じ)。 - 条件付き入力を許可: 入力基準に基づいてこのノードを条件付きでトリガーするロジックを有効にします。
出力
ナレッジノードは、下流ノードが消費できる3つの出力変数を生成します。このナレッジノードから入力を受け取るように別のノード(マルチモーダルなど)を設定する場合、そのノードの 入力変数セレクター で使用する出力タイプを選択します。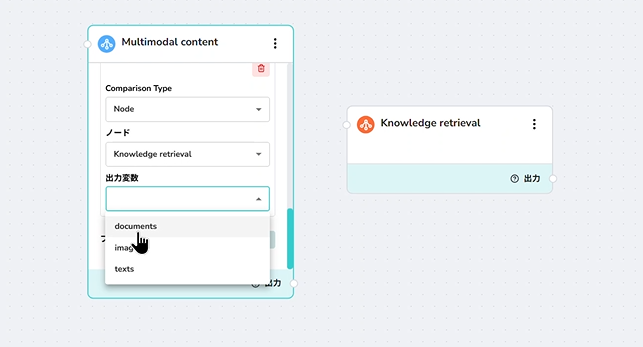
出力選択ドロップダウン(documents/texts/images)は、ナレッジノード自体ではなく、消費側ノードの 設定に表示されます。上記のスクリーンショットは、ナレッジ検索ノードから入力を受け取るように設定されたマルチモーダルノードのこのセレクターを示しています。
出力タイプ
| 出力 | 説明 | 最適な用途 |
|---|---|---|
| documents | テキストコンテンツ、画像、ドキュメント参照(ソースファイル、ページ番号)、およびメタデータ(スコア、チャンクID)を含む完全な検索ペイロード。 | 完全なコンテキストとソースの帰属が必要な場合、または異なるコンテンツタイプを個別に処理したい場合。 |
| texts | 取得されたチャンクから抽出されたテキストコンテンツのみを結合したもの。 | メタデータのオーバーヘッドなしにテキスト情報のみが必要な単純なLLMプロンプト。 |
| images | 取得されたチャンクから抽出された画像のみ。 | ナレッジベースから視覚コンテンツを分析する必要があるビジョン対応モデル。 |