一般的な使用法
このノードは、音声対応ワークフローの中心であり、カスタマーサービスボット、インタラクティブアシスタント、またはアクセシビリティツールによく使用されます。設定例
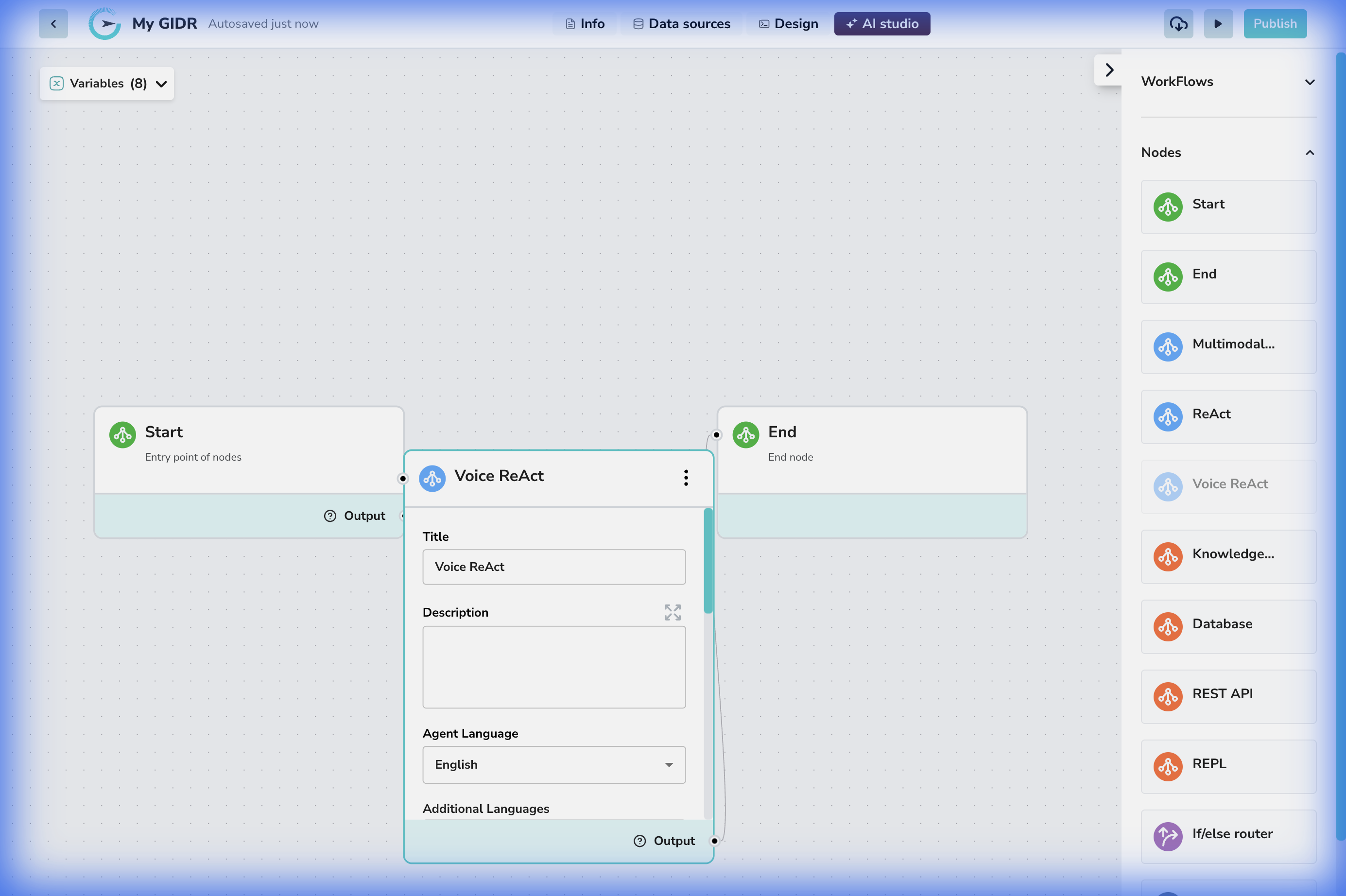
- 接続: 開始ノードと終了ノードの間に直線的に接続されます。
- 音声対話: ノードは、音声認識(STT)と音声合成(TTS)の複雑さを自動的に処理します。
設定の詳細
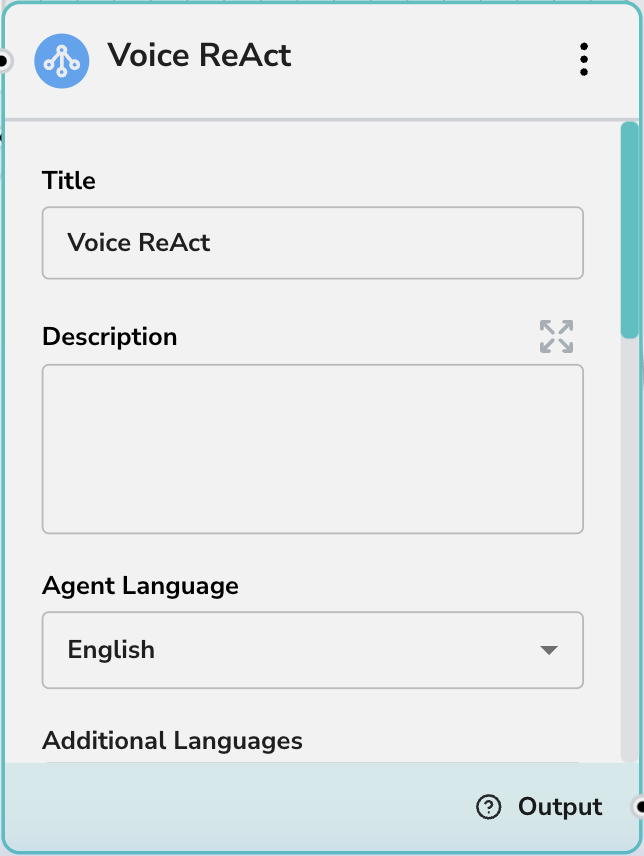
コア設定
- タイトル: 音声エージェントにペルソナベースの名前を付けます(例:「サポート音声ボット」)。
- 説明: エージェントの役割に関する内部メモ。
- エージェント言語: エージェントが理解し話す主要言語(例:「英語」)。
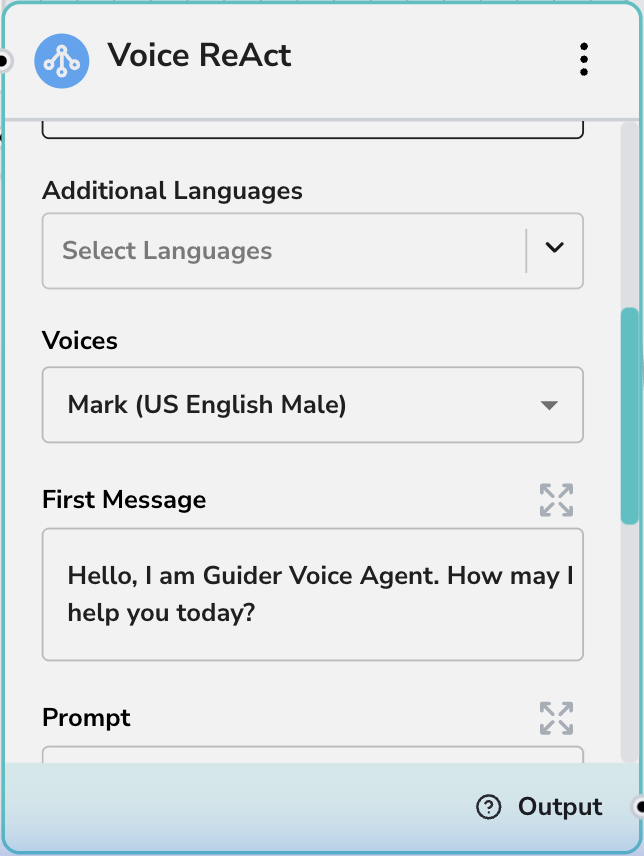
音声とパーソナリティ
- 追加言語: 多言語ユーザーベースをサポートする場合、エージェントが処理できる必要のある他の言語を選択します。
- 音声: ブランドやユースケースに最も適した特定の音声モデル(例:「Gemini - Mark (US English Male)」)を選択します。
- 最初のメッセージ: セッション開始時にエージェントが話す冒頭のセリフ(例:「こんにちは、GIDR音声エージェントです。本日はどのようなご用件でしょうか?」)。
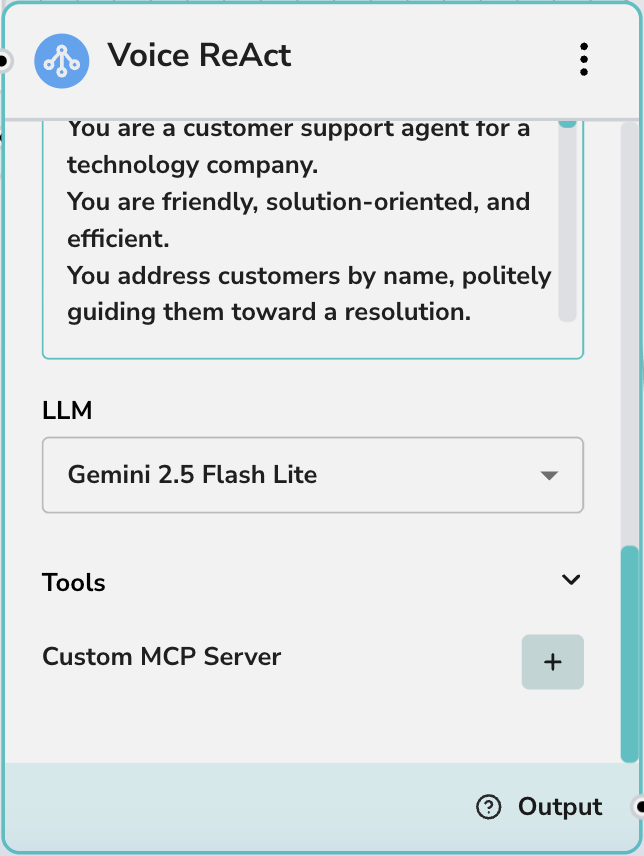
プロンプトとツール
- プロンプト: エージェントの動作、知識の境界、およびパーソナリティ特性を定義するシステム指示。
- LLM: 会話を動かす基盤となるモデル(例:Gemini 2.5 Flash Lite)。
- ツール: ユーザーと話している間にこの音声エージェントが呼び出すことができる特定のツールを有効にします。
- カスタムMCPサーバー: カスタムModel Context Protocolサーバーを使用してエージェントの機能を拡張します。