一般的な使用法
マルチモーダルノードは、ワークフロー内でLLMを呼び出すための主要なポイントです。さまざまなコンテンツタイプを処理し、テキスト、画像、またはビデオ入力を分析し、特定のプロンプトと設定に基づいてインテリジェントなテキスト出力を生成するように設計されています。このノードは、データを大規模言語モデルの推論能力と接続します。設定例
- 接続: ノードは、「開始」ノードまたはその他の任意のノードと入力または出力のために接続できます。
- 設定: 設定パネルでは、モデルの動作を詳細に設定できます。
設定の詳細
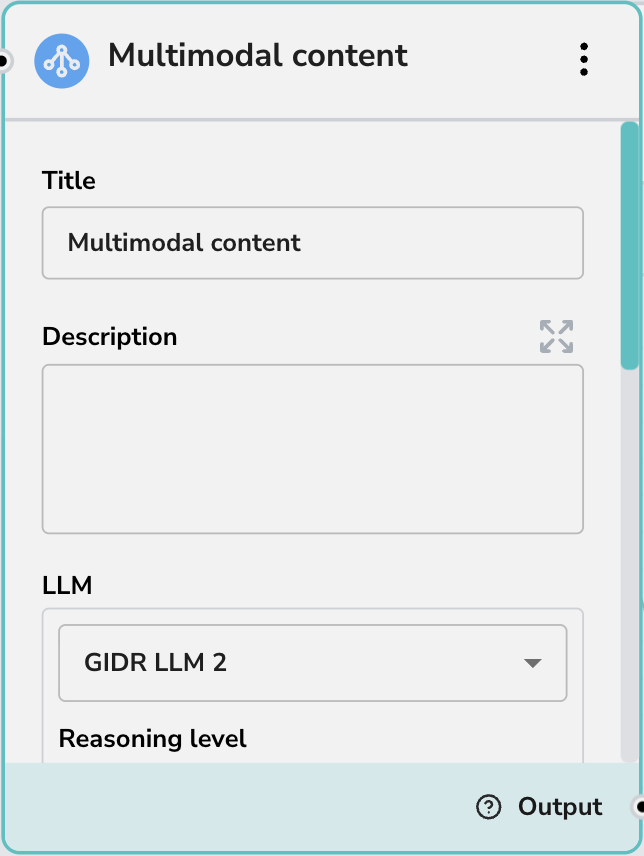
コア設定
- タイトル: ノードにわかりやすい名前を付けます(例:「領収書画像の分析」)。
- 説明: ドキュメントの目的のために、このノードが行うことの簡単な要約を追加します。
LLM設定
- LLM: このノードを駆動する特定の大規模言語モデルを選択します(例:GIDR LLM 2)。下記の機能は、選択したLLMがサポートしているかどうかにづいて動的に表示されます。
- 推論レベル: モデルの分析の深さを制御します。オプションには、低(高速)、中(バランス)、高(徹底的)があります。このオプションは、選択したLLMが推論機能をサポートしている場合にのみ表示されます。
- ウェブ検索: 検索クエリを実行し、関連する最新の結果を返すことで、Webから情報を取得します。このオプションは、選択したLLMがツールベースのWeb検索をサポートしている場合にのみ表示されます。
- 参照による入力の取得: 直接の値ではなくURL参照を介して入力を処理し、モデルが大きなドキュメント、ビデオ、オーディオファイルを処理できるようにします。このオプションは、選択したLLMが参照ベースの入力をサポートしている場合(例:Google Gemini)にのみ表示されます。
ウェブ検索プロンプトのガイドライン
ウェブ検索が有効になっている場合、プロンプトでは、事前定義されたデータに依存するのではなく、いつweb_search ツールを使用するかをLLMに明確に指示する必要があります。重要な原則は、提供された入力にまだ含まれていないリアルタイム、時間的制約のある、または外部で検証可能な情報に対してのみWeb検索を呼び出す必要があるということです。データがコンテキスト内に存在する場合、モデルは決してツールを呼び出してはいけません。以下は、この動作を強制するプロンプトの例です:
参照による入力の取得
参照による入力の取得 が有効になっている場合、モデルは直接の値ではなくURL参照を介して入力を処理します。これにより、標準の入力制限を超える大きなドキュメント、ビデオ、オーディオファイルを処理できます。参照による入力の取得は、現在Google Gemini LLMでのみサポートされています。
| メディアタイプ | 容量とサイズ制限 | サポートされている形式 |
|---|---|---|
| 画像 | • 最大 7 MB | PNG, JPEG, WEBP, HEIC, HEIF |
| ドキュメント | • ファイルあたり最大1,000ページ • 最大 50 MB | PDF, プレーンテキスト |
| ビデオ | • ~45分 (音声あり) • ~1時間 (音声なし) | FLV, MOV, MPEG, MP4, WEBM, WMV, 3GPP |
| オーディオ | • ~8.4時間 | AAC, FLAC, MP3, M4A, MPEG, MPGA, WAV, OGG |
プロンプトと会話履歴
- プロンプト: AIへの主な指示(例:「入力の詳細な分析を提供してください」)。静的テキストと動的変数を混在させることができます。
- 以前のやり取りの数: モデルに渡される会話履歴(コンテキスト)の量を制御します。「0」は履歴なし(ステートレス)を意味します。
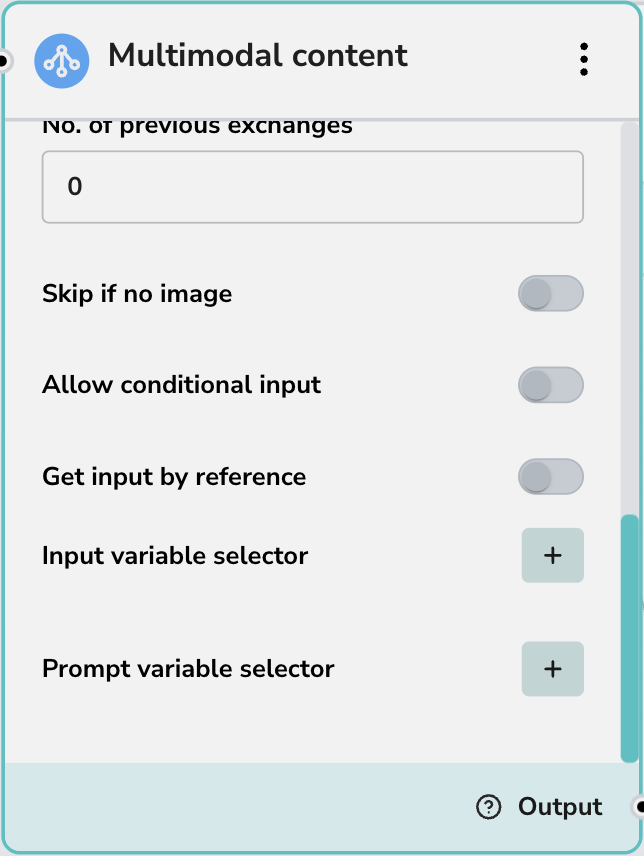
詳細オプション
- 画像がない場合はスキップ: 入力に画像データが含まれていない場合、このノードを自動的にバイパスします。これは、テキストのみとマルチモーダルの両方の入力をエラーなしで適切に処理できるワークフローを構築するのに役立ちます。
- 条件付き入力を許可: 入力基準に基づいてこのノードを条件付きでトリガーするロジックを有効にします。
-
変数セレクター:
- 入力変数セレクター: 特定の入力変数をノードにマッピングします。
- プロンプト変数セレクター: 変数(例:ユーザー名、日付)をプロンプトに直接注入します。